
Windows環境で、写真などの画像に表示されている文字からテキストを取り出す(文字認識:OCR)方法としていくつかの方法がありますが、ここでは、以下の3種類の方法を紹介します。
- Windows 11に標準搭載されているSnipping Toolアプリを使った方法
- Googleが提供しているオンラインストレージ「Googleドライブ」を使った方法
- Microsoftが提供しているWindows向けのカスタマイズツール「PowerToys」に搭載されている「Advanced Paste」を使った方法
目次
Snipping Tool(Windows 11)
Windows 11なら、標準搭載のSnipping Toolで画像からテキストデータを抽出できます。手順は、次のとおりです。
まず、スクリーンショットを撮影したり、手動でSnipping Toolを起動して文字認識させたい画像を開き、ツールバーから「テキストアクション」ボタンをクリックします。
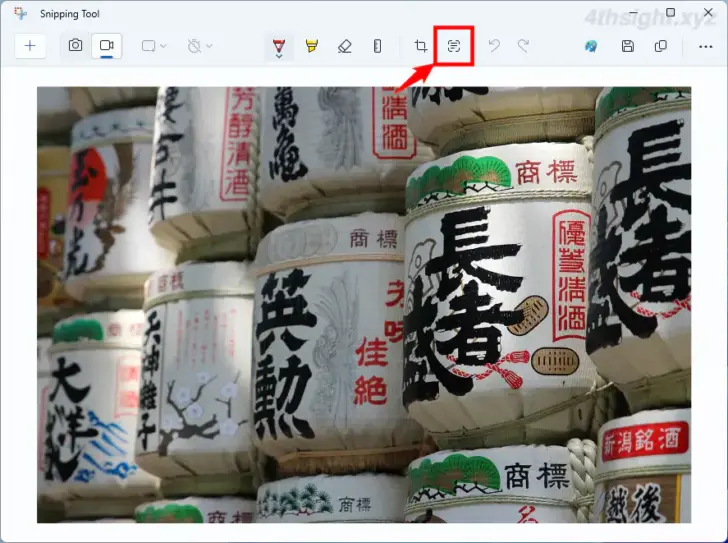
すると、画像が解析され画像内のテキスト部分がハイライト表示されます。
ハイライト表示された部分は、一部を選択したり全選択してテキストデータとしてクリップボードにコピーすることができます。
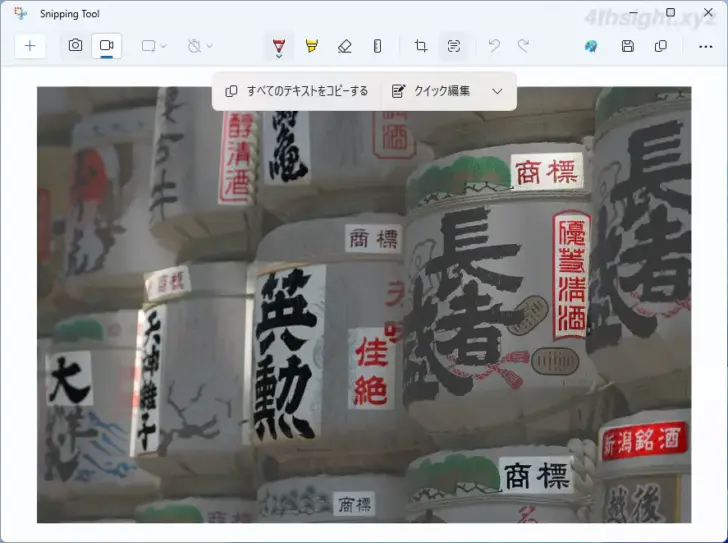
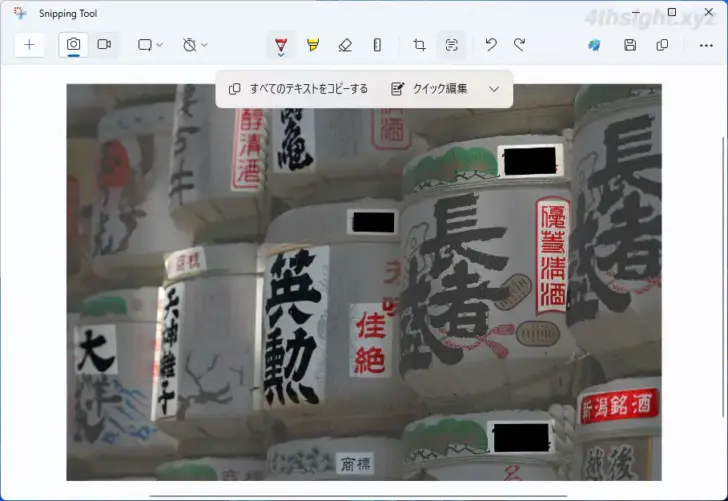
また、メニューの「クイック編集」からは、画像内に表示されているメールアドレスや電話番号といった個人情報部分を自動的に黒塗りにすることができ、選択した部分だけを黒塗りにすることもできます。
Googleドライブ
Googleアカウントを持っているなら、Web版の「Googleドライブ」を利用することで、専用ソフトに引けを取らない精度で文字を抽出することができます。
まず、WebブラウザでGoogleドライブにアクセスします。(Googleアカウントでログインしていない場合は、ログインします。)
ここでは、Google Chromeを利用しています。
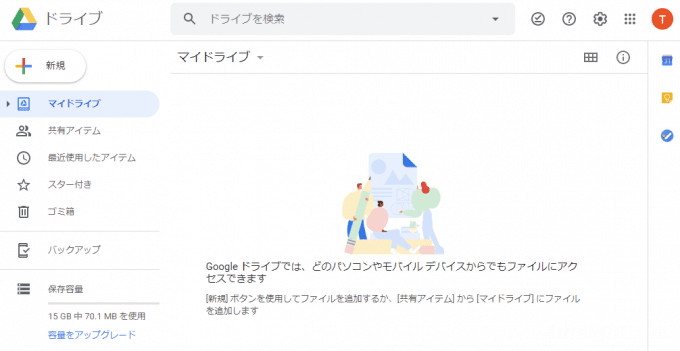
Googleドライブのページを開いたら、文字認識させたい画像ファイルをドラッグするなどしてアップロードします。
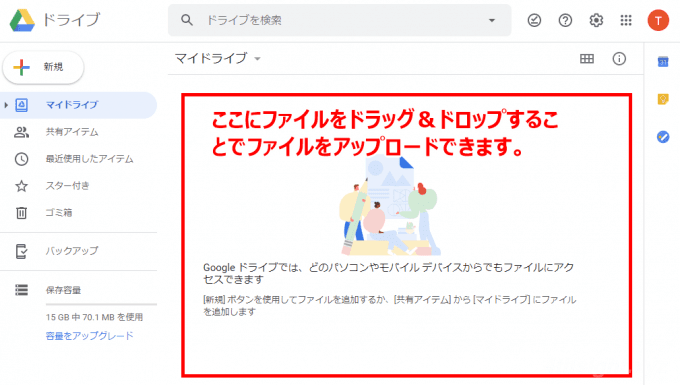
ファイルをアップロードしたら、Googleドライブ上でファイルを右クリックして、メニューから「アプリで開く」>「Googleドキュメント」を選択します。
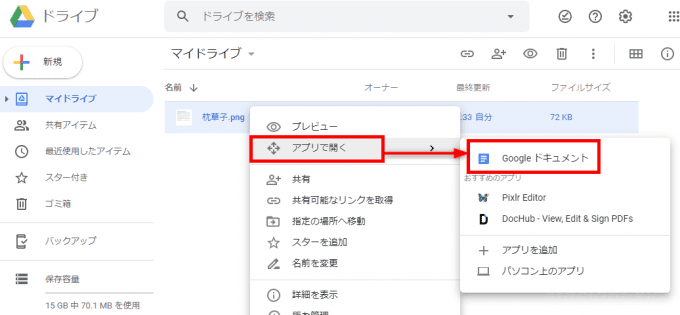
すると、アップロードしたファイルの文字認識処理が実行され、処理が完了するとGoogleドキュメントが開き、元の画像と抽出されたテキストデータが表示されます。
手書き文字でなければ、以下のようにかなり高精度で変換できます。また、横書きだけでなく縦書きでも問題なくテキストを抽出できます。

Advanced Paste
Advanced Pasteは、Microsoftが提供しているWindows 10、11向けのカスタマイズツール「PowerToys」に含まれている機能で、Advanced Pasteを使うことで、画像をクリップボードにコピーしたときに、画像に表示されているテキストを認識・抽出してテキストデータとして貼り付けることができます。
PowerToysの概要やインストール方法は、以下の記事をご覧ください。

Advanced Pasteで画像からテキストを抽出したいときは、まず画像ファイルをフォトアプリなどで開いて画像データをクリップボードにコピーします。
次に、抽出したテキストデータを貼り付けるアプリ上で、Advanced Pasteのショートカットキー「Windowsキー+Shift+V」を押します。
すると、貼り付けメニューが表示されるので「画像からテキストへ」を選択することで、画像内に表示されているテキストデータが認識・抽出され、テキストデータとして貼り付けることができます。
以下の画像では、抽出したテキストデータをメモ帳に貼り付けています。
あとがき
いずれの方法も、手書き文字でないならかなりの高精度で抽出できますが、手書きの文字や、文字に色が付いていたり、箇条書きや表などが含まれる場合では、うまく抽出できない場合もありますが、目視&手作業で抽出するのに比べれば、十分に有用ではないでしょうか。ご活用あれ。